PIM stands for Product Information Management. It helps big retailers efficiently acquire, author, and publish product information. More details about functionality could be found at the corporate web site. Do not be confused, PIM recently was renamed to “Product 360”.
Screenshots
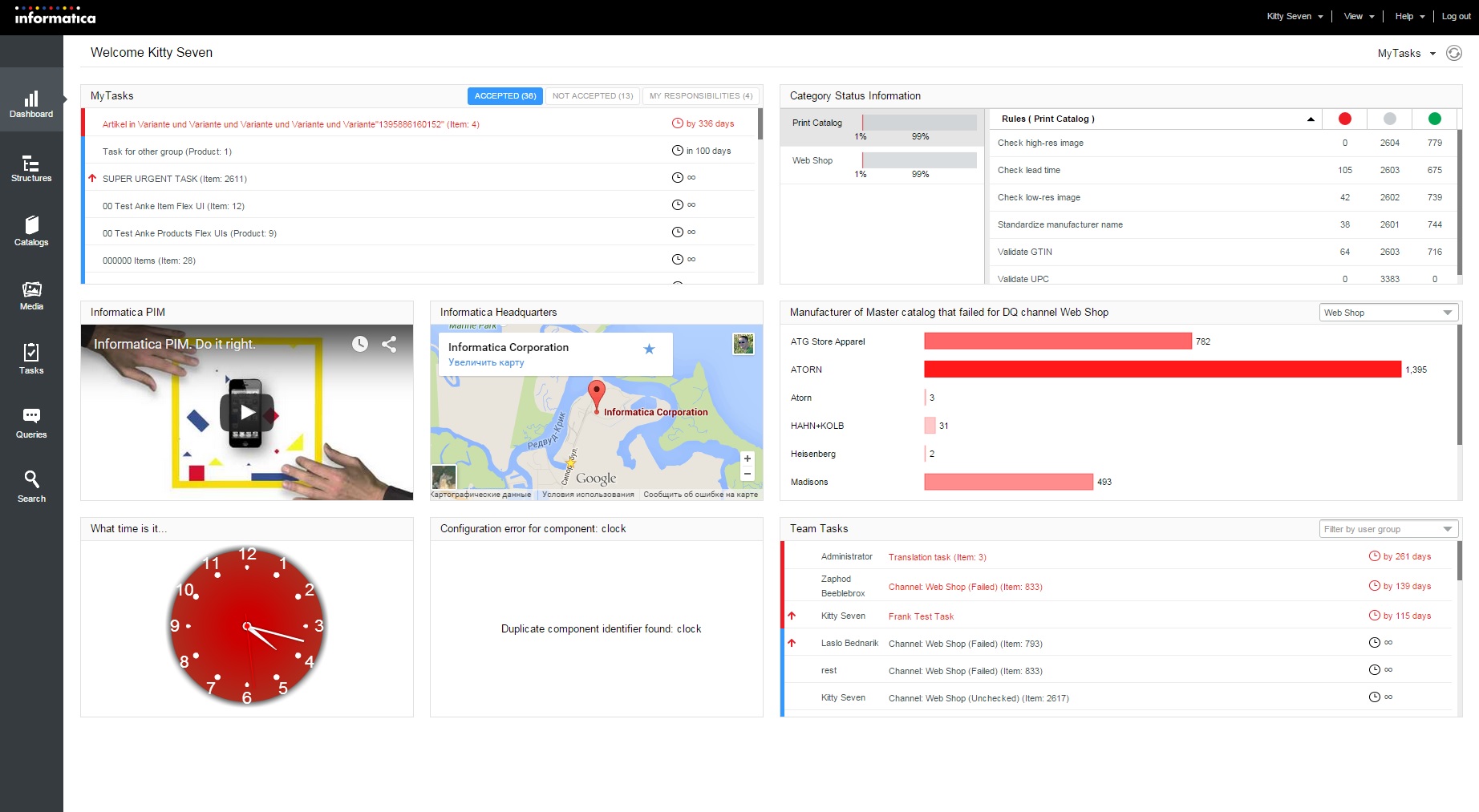 PIM – Dashboard |
 PIM – Product Details |
 PIM – Flexible UI |
 PIM – Rich Client |
Videos
- Informatica PIM. Do it right.
- Informatica PIM-MDM integration demo
- Data quality rules within Informatica PIM
The team
The whole development team consists of about 50 people. We have 5 scrum teams. Four of them are in Germany, Stuttgart. The last (but not least) is in Russia, Saint-Petersburg. I joined the Russian PIM team in January, 2015. In the best times our team consisted of 11 people.
We use the Scrum framework and have been constantly improving our processes to achieve the best possible results.
My role
My primary role is to lead development of the Web UI. Other tasks include scrum mastering and improving other parts of the system. Sometimes I participate in job interviews as a technical expert.
A bit of history
In its usual way Informatica acquired Heiler Software AG in 2013 together with the PIM project that lasted already for several years. It is exactly the same way how I came to Informatica when Siperian Inc. where I was working was bought in 2011.
Architecture
The system originally was created by German developers and its core is of very good quality. The system consists of the core server part that has several very well-designed APIs: Command API, Report API, REST API, OSGi extension points. It allows to customize easily almost every part of the system. So, there is a big customer ecosystem around the project.
The system core is database-independent. It supports Oracle and MySQL as the primary databases, but it could work with others. The data layer operates with business model artifacts. It is very optimized for work with large data sets. It consists of two main parts: entity detail access and list access. The entity detail access provides CRUD operations whereas the list access provides high-performance read-only methods to fetch entities data in a table form. PIM programmers are saved from creating direct DB calls which allows to use caching on different levels and speeds up the whole process.
The data schema is predefined, but it has a good reserve of different fields that customers could use on they own. Also there is a special configuration tool that allows easy tuning of all data schema types and fields.
Technologies
Major involved technologies are J2EE, Eclipse OSGI, Vaadin, Guice, Spring, MS SQL Server, REST, Swing (for the rich client). We use Jetty servlet container.
The rich client is based on the Eclipse platform, so it inherits all its good sides and looks pretty well. However, some time ago it was decided the system needs a Web UI to be competitive. Our team is responsible for this important part of the system.
The Web UI is based on the Vaadin framework. I always had been skeptical about conversion of Java into JavaScript, but after working a while with the project I noticed that UI could be created very fast, it has a good quality and it is written with good old Java language.
Another interesting part of the Web UI is heavy usage of Guice framework for dependency injection. It requires time to get used to this style of coding, but it is worth it. The code becomes much clearer, easily configurable and what is most important, easily testable.
For unit testing we use Mockito framework.
Codebase
Core
- 443 plugins, ~12000 classes
- Tests: 130 plugins, ~2200 classes
Web UI
- 47 plugins, ~1700 classes
- Tests: 17 plugins, ~200 classes